COMIC: Agentic Sketch Comedy Generation Preprint 2026 Susung Hong , Brian Curless , Ira Kemelmacher-Shlizerman , Steve Seitz Paper Project
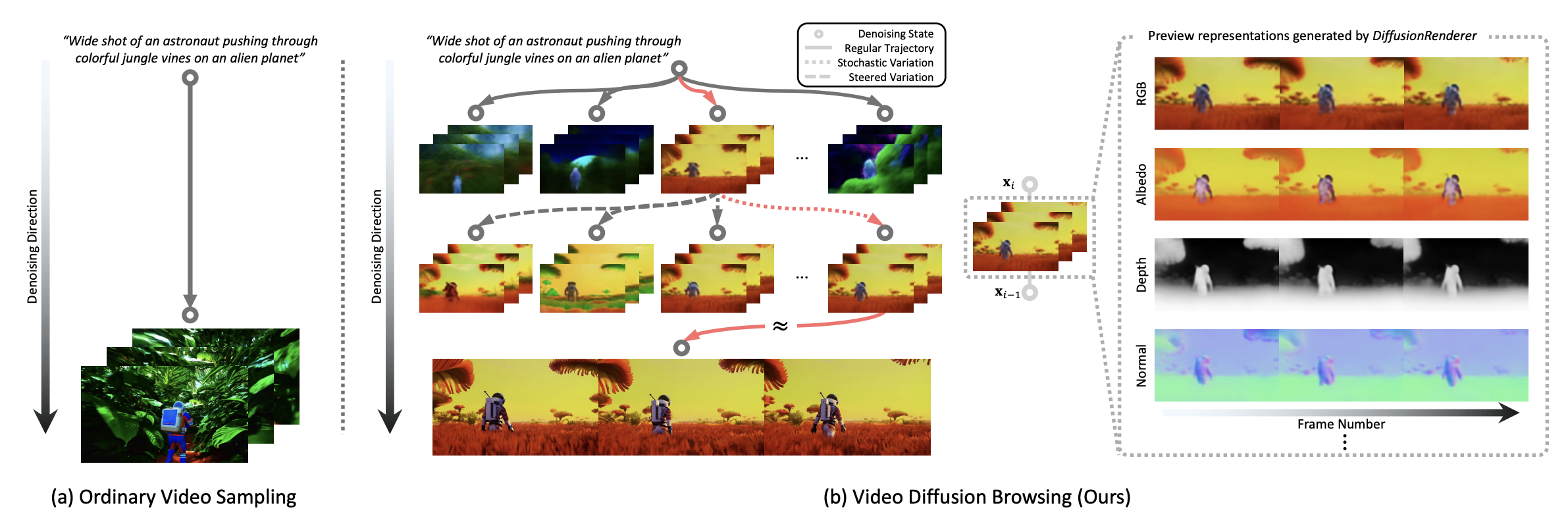
DiffusionBrowser: Interactive Diffusion Previews via Multi-Branch Decoders Preprint 2025 Susung Hong , Chongjian Ge , Zhifei Zhang , Jui-Hsien Wang Paper Project
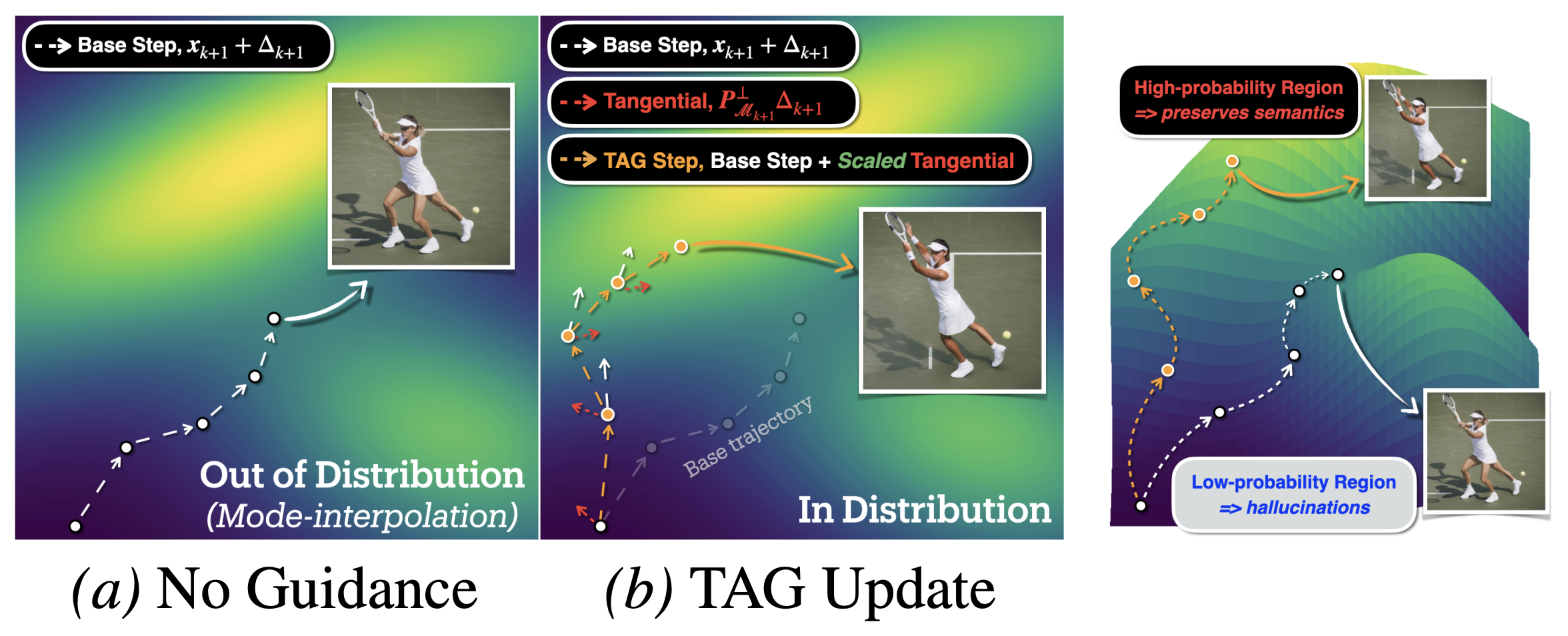
TAG: Tangential Amplifying Guidance for Hallucination-Resistant Sampling ICML 2026 Hyunmin Cho* , Donghoon Ahn* , Susung Hong* , Jee Eun Kim , Seungryong Kim , Kyong Hwan Jin Paper Project
MusicInfuser: Making Video Diffusion Listen and Dance CVPR 2026 Susung Hong , Ira Kemelmacher-Shlizerman , Brian Curless , Steven M Seitz Paper Project
Perturb-and-Revise: Flexible 3D Editing with Generative Trajectories CVPR 2025 Susung Hong , Johanna Karras , Ricardo Martin-Brualla , Ira Kemelmacher-Shlizerman Paper Project
Spatiotemporal Skip Guidance for Enhanced Video Diffusion Sampling CVPR 2025 Junha Hyung* , Kinam Kim* , Susung Hong , Min-Jung Kim , Jaegul Choo Paper Project
Smoothed Energy Guidance: Guiding Diffusion Models with Reduced Energy Curvature of Attention NeurIPS 2024 Susung Hong Paper Project
Effective Rank Analysis and Regularization for Enhanced 3D Gaussian Splatting NeurIPS 2024 Junha Hyung , Susung Hong , Sungwon Hwang , Jaeseong Lee , Jaegul Choo , Jin-Hwa Kim Paper Project
Retrieval-Augmented Score Distillation for Text-to-3D Generation ICML 2024 Junyoung Seo* , Susung Hong* , Wooseok Jang* , Inès Hyeonsu Kim , Minseop Kwak , Doyup Lee , Seungryong Kim Paper Project
Depth-aware guidance with self-estimated depth representations of diffusion models PR 2024 Gyeongnyeon Kim , Wooseok Jang , Gyuseong Lee , Susung Hong , Junyoung Seo , Seungryong Kim Paper Project
DirecT2V: Large Language Models are Frame-Level Directors for Zero-shot Text-to-Video Generation ICMLW 2023 Susung Hong , Junyoung Seo , Sunghwan Hong , Heeseong Shin , Seungryong Kim Paper Project
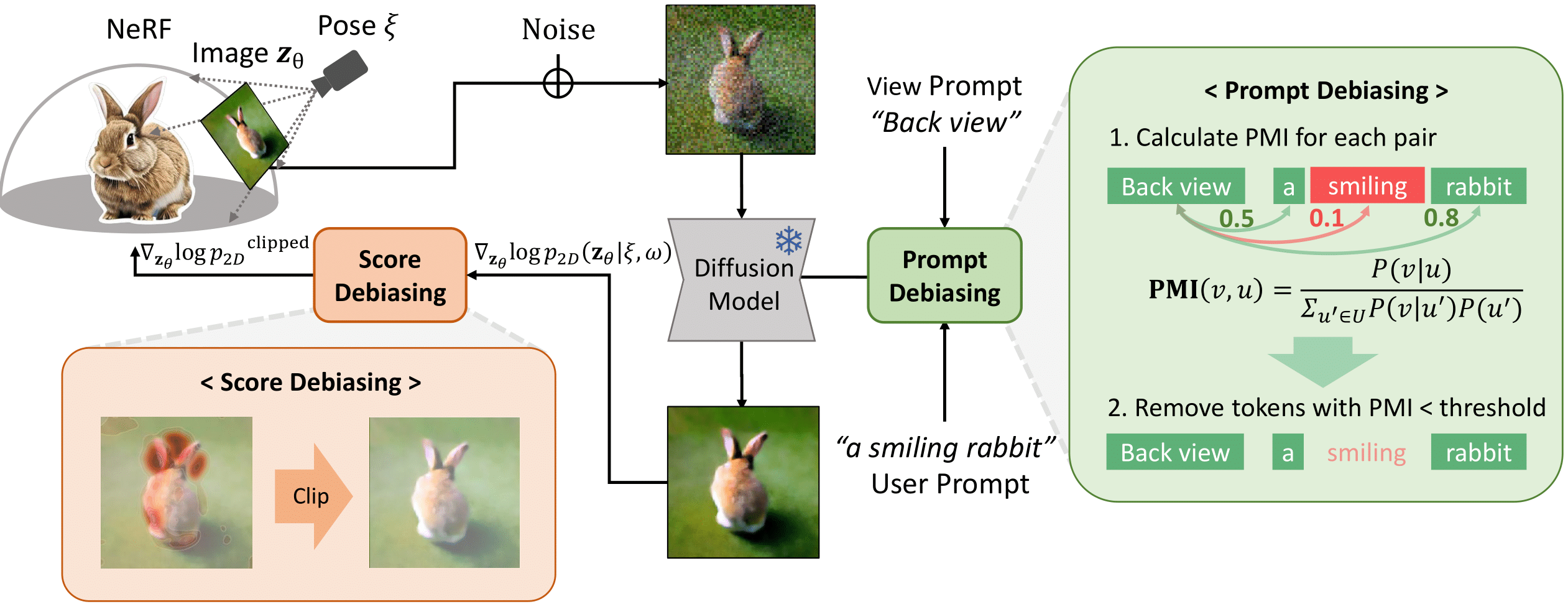
Debiasing Scores and Prompts of 2D Diffusion for View-consistent Text-to-3D Generation NeurIPS 2023 Susung Hong* , Donghoon Ahn* , Seungryong Kim Paper Project
Improving Sample Quality of Diffusion Models Using Self-Attention Guidance ICCV 2023 Susung Hong , Gyuseong Lee , Wooseok Jang , Seungryong Kim Paper Project
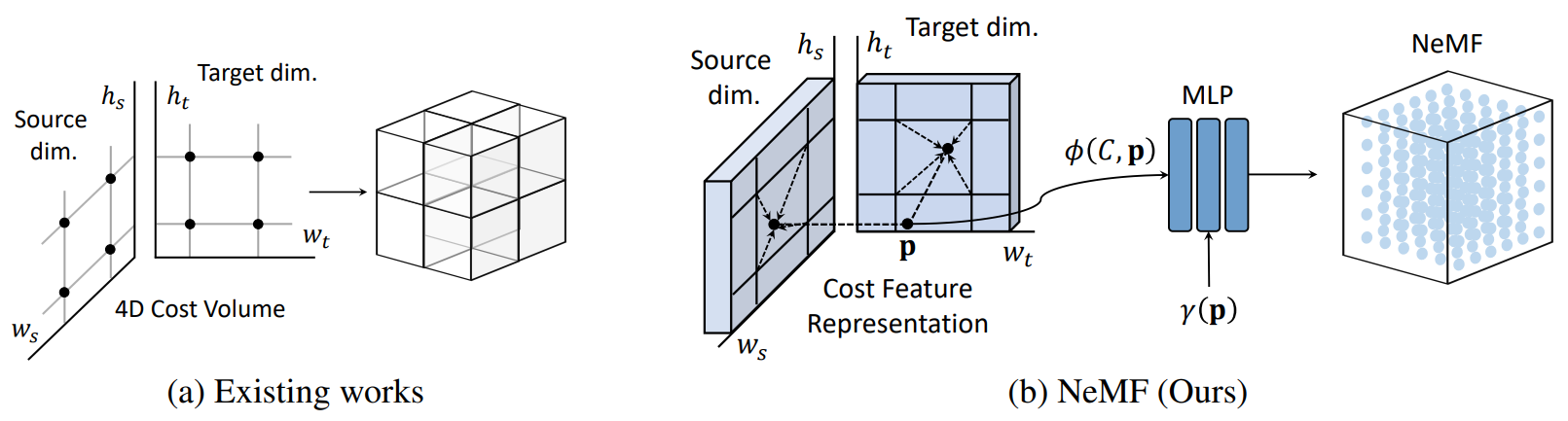
Neural Matching Fields: Implicit Representation of Matching Fields for Visual Correspondence NeurIPS 2022 Sunghwan Hong , Jisu Nam , Seokju Cho , Susung Hong , Sangryul Jeon , Dongbo Min , Seungryong Kim Paper Project